
Biblioteki HL++ podzielić można na dwa rodzaje: 1) ułatwiające programowanie matematyczne (m.in. metod numerycznych, sieci neuronowych, wykresów) oraz 2) dostarczające złożonych typów danych (m.in. tekst, data, macierz). Dla złożonych typów danych przygotowano wiele funkcji, umożliwiających wygodną nimi manipulację. Obiekty standardowego C++ takie jak tablica (array) czy napisy (string) przechowują elementy, jednak tablica nie ma własnych funkcji, a napisy posiadają tylko kilka podstawowych funkcji konwersji, przez co ich funkcjonalność jest ograniczona. Obiekty HL++ takie jak tekst (text) czy macierz (matrix) mają zdefiniowanych wiele funkcji, dzięki czemu posługiwanie się nimi jest łatwe i wygodne.
Przykładowo, aby zadeklarować macierz o wymiarach 10×20 wypełnioną zerami, pisze się:
matrix A = zeros(10,20);
Aby dodać dwie macierze, piszę się:
A+B
Obliczanie wyznacznika to:
det(B)
Itd.
Funkcje elementarne (elfun)
Biblioteka funkcji elementarnych nosi nazwę „elfun”. Dostarcza takie funkcje jak rnd, round, sign, sqr itp. Dołącza się ją za pomocą:
#include <elfun.h>
Przykład
double x1 = rnd(); double x2 = round(5.23);
Zmienna x1 przyjmuje wartość losową z zakresu [0,1]. Dla x2 wywoływana jest funkcja zaokrąglająca liczbę 5.23 do liczby całkowitej 5.
Tekst (text)
Aby posłużyć się zmienną typu text, konieczne jest dołączenie biblioteki tego typu do programu:
#include <text.h>
Ze zmienną typu text można wykonywać wiele operacji. Wszystkie dostępne funkcje opisane są w Pomocy HL++.
Przykład
Text sciezka = "C://Dane//"; Text nazwa_pliku = "plik.csv"; Text nazwa_do_otwarcia = sciezka+nazwa_pliku;
Połączenie ścieżki z nazwą pliku odbywa się za pomocą operacji dodawania. W wyniku otrzymuje się tekst „C://Dane//plik.csv”.
Data (date)
Aby posłużyć się zmienną typu date, konieczne jestdołączenie biblioteki tego typu do programu:
#include <date.h>
Dostępne funkcje opisane są w Pomocy HL++.
Przykład
date d1 = "2010-11-02"; cout<<"Data 1: "<<d1<<endl; date d2 = "2010-12-12"; cout<<"Data 2: "<<d2<<endl; date d3 = ymfirst(d2); cout<<"Data 3: "<<d3<<endl; cout<<"Roznica dat 3 i 1 wynosi "<<d3-d1<<" dni";
Najpierw deklarowane i wyświetlane są zmienne d1 i d2. Data d3 jest ustawiana na pierwszy dzień miesiąca daty d2. Na koniec wyświetlana jest różnica dat. Wynik działania programu:
Data 1: 2010-11-2
Data 2: 2010-12-12
Data 3: 2010-12-1
Roznica dat 3 i 1 wynosi 29 dni
Wektor (vector)
Wektor liczb całkowitych jest elementarnym typem danych. Typ vector jest bardziej obiektem technicznym niż praktycznym. Najczęściej korzystanie z niego jest transparentne dla użytkownika. Aby utworzyć obiekt wektorowy o większej funkcjonalności, należy użyć typu matrix i wybrać jeden z wymiarów równy 1.
Obiekt vector wykorzystuje się np. jako:
- indeks kolejności podczas sortowania. Wynikiem funkcji ‘sort’ może być permutacja ciągu 1,2,3…n
- indeks wartości logicznych podczas filtrowania. Argumentem funkcji ‘filter’ jest ciąg zero-jedynkowy (0 oznacza false, 1 true).
Dołączenie do programu:
#include <vector.h>
Dostępne funkcje opisane są w Pomocy HL++.
Przykład
vector a = c(5,2,7,33);
vector b = $(10,10,100);
vector c = vzeros(5);
a.display("a");
b.display("b");
c.display("c");
Tworzony jest wektor 'a’ o wartościach zdefiniowanych stałymi, wektor 'b’ określony za pomocą sekwencji oraz 'c’ wypełniony zerami. Wynik działania programu:
a
5 2 7 33
b
10 20 30 40 50 60 70 80 90 100
c
0 0 0 0 0
Dane (data)
Dane (data) to podstawowy typ danych, stanowiący bazę dla typów matrix i table. Obiekt ten gromadzi elementy dowolnego typu w prostokątnej tablicy, posiadającej etykiety kolumn i wierszy. Ponieważ elementy mogą być dowolnego typu, obiekt taki nazywa się kontenerem. Data posiada tylko takie funkcje, które można wykonać niezależnie od tego, jakie elementy są przechowywane w jego komórkach. Można więc obiekt data np. obrócić, transponować, wybrać wiersz lub kolumnę, ale nie można wykonywać operacji arytmetycznych.
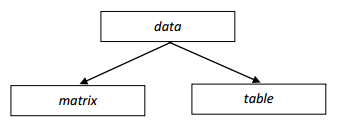
Z obiektu data dziedziczą obiekty matrix i table. Oznacza to, że wszystkie funkcje, które można wywołać dla obiektu data, są również dostępne dla tych dwóch obiektów. Matrix to typ danych o elementach liczbowych. Table to typ danych o elementach, które są tekstem. W programie używa się obiektów pochodnych – macierzy i tabel – a nie wprost typu bazowego. Należy jednak znać metody dostępne dla data, ponieważ te same metody są dostępne dla typów pochodnych. Dostępne funkcje opisane są w Pomocy HL++.
Macierz (matrix)
Obiekt matix to macierz liczbowa, której wiersze i kolumny mogą być (ale nie muszą) oznaczone etykietami. Obiekt dziedziczy wszystkie funkcje z obiektu data.
Dołączenie do programu:
#include <matrix.h>
Dostępne funkcje opisane są w Pomocy HL++.
Przykład
matrix A = "1 2; \
3 4";
matrix B = "0 1; \
1 0";
matrix C = A*B + 2.0*A;
matrix D = inv(B);
C.display("C");
D.display("D");
Tworzone są macierze A i B o wymiarach 2×2. Następnie obliczane są macierze C i D. Na koniec następuje wyświetlenie wyniku:
C
2 6
9 8
D
0 1
1 0
Tabela (table)
Obiekt table to macierz tekstowa, której wiersze i kolumny mogą być oznaczone etykietami. Obiekt dziedziczy wszystkie funkcje z obiektu data.
Dołączenie do programu:
#include <table.h>
Dostępne funkcje opisane są w Pomocy HL++.
Przykład
table t(10,1);
t.test();
t.display("t");
table t2 = cut(t,c(3.0,5.0,7.0));
t2.display("t2");
table tt = apply(t,t2,mean);
tt.display("tt");
Tworzona jest tabela 't’ o 10 wierszach i 1 kolumnie, która następnie jest wypełniana wartościami testowymi (liczbami od 1 do 10):
t
C1
R1 1
R2 2
R3 3
R4 4
R5 5
R6 6
R7 7
R8 8
R9 9
R10 10
Potem tworzona jest tabela t2, w której wartości 't’ są pogrupowane w przedziały zdefiniowane wektorem c(3.0,5.0,7.0):
t2
C1_CUT
R1 (-Inf,3.00]
R2 (-Inf,3.00]
R3 (-Inf,3.00]
R4 (3.00,5.00]
R5 (3.00,5.00]
R6 (5.00,7.00]
R7 (5.00,7.00]
R8 (7.00,Inf]
R9 (7.00,Inf]
R10 (7.00,Inf]
Na koniec powstaje tabela tt, w której dla przedziałów t2 są obliczane średnie wartości 't’:
tt
(-Inf,3.00] (3.00,5.00] (5.00,7.00] (7.00,Inf]
2.000000 4.500000 6.500000 9.000000
Macierz rzadka (sparse)
Macierze rzadkie znajdują się w bibliotece „sparse”. Dołącza się ją za pomocą:
#include <sparse.h>
Na macierzach tego typu można wykonywać podobne operacje co na zwykłych macierzach, chociaż lista metod i funkcji jest nieco krótsza. Zaletą takich obiektów jest oszczędność pamięci, ponieważ zapamiętywane są tylko elementy istotne (różne od 0). Dzięki mechanizmom pakowania i synchronizacji operacje arytmetyczne na takich obiektach mogą być wykonywane szybciej niż na zwykłych macierzach. Macierze rzadkie są wykorzystywane do reprezentacji połączeń w sieciach neuronowych, opisanych w dalszej części.
Przykład
sparse A = speye(4,4);
A.display("A");
sparse B = 2.0*A;
B.display("B");
Tworzona jest macierz identycznościowa A o wymiarach 4×4 oraz macierz B z wartościami 2 na przekątnej głównej. Wynik działania programu:
A:
1 0 0 0
0 1 0 0
0 0 1 0
0 0 0 1
B:
2 0 0 0
0 2 0 0
0 0 2 0
0 0 0 2
Kompresja danych (gzip)
Do odczytu/zapisu danych skompresowanych służy biblioteka „gzip”. Dołącza się ją za pomocą:
#include <gzip.hpp>
Przykład
table dane; read_data(dane,"dane.txt"); write_data(dane,"dane.txt"); matrix wyniki; read_data(wyniki,"wyniki.txt"); write_data(wyniki,"wyniki.txt");
Kompresowanie danych jest transparentne dla użytkownika. M.in. nie podaje się rozszerzenia gz – w przykładzie operuje się na plikach „dane.txt.gz” i „wyniki.txt.gz”.
Metody numeryczne (numproc)
Podstawowe funkcje numeryczne znajdują się w bibliotece „numproc”. Dołącza się ją za pomocą:
#include <numproc.h>
Dostępne jest:
- całkowanie numeryczne
- różniczkowanie numeryczne
- wyszukiwanie ekstremów
- wyszukiwanie miejsc zerowych
- minimalizacja wielowymiarowa
- wielowymiarowe dopasowywanie nieliniowe
Przykład 1.
Rozwiązywanie równania 2.5*sin(x)+1.35*x-0.4 = 0:
// definicja funkcji, której miejsce zerowy jest szukane
double funkcja_sinx_x(double x)
{
return 2.5*sin(x)+1.35*x-0.4;
}
// fragment programu głównego
double x0 = fzero(funkcja_sinx_x,0.0,1e-6);
Parametr 0.0 oznacza wartość początkową. Parametr 1e-6 to dokładność znalezionego rozwiązania x0.
Przykład 2.
Dopasowanie funkcji tanh z 4 parametrami do danych:
// definicja funkcji, którą chcemy dopasować
double funkcja_tanh4(double x,matrix &par)
{
return par(1)*tanh(par(2)*x+par(3))+par(4);
}
// fragment programu głównego
matrix dane.readtxt("dane.txt");
matrix x=dane["WIEK"],
y=dane["PD"];
matrix par=zeros(4,1);
fits(x,y,funkcja_tanh4,par,1e-6);
Parametry dopasowania są zwrócone w zmiennej par.
Sieć neuronowa (neural_net)
Sieci neuronowe znajdują się w bibliotece „neural_net”. Dołącza się ją za pomocą:
#include <neural_net.h>
Biblioteka „neural_net” umożliwia konstrukcję i trenowanie jednokierunkowych sieci neuronowych, składających się z 3 warstw. Zaimplementowane są efektywne, generalizujące metody uczenia, jak i metody dopasowania do danych, minimalizujące błąd. Zbiory danych można podzielić na kilka części (standardowo: konstrukcyjna, walidacyjna, testowa). Wybrać można między standardowymi funkcjami przejścia (logit, tanh, liniowa). Przygotowanych jest wiele funkcji do manipulacji architekturą sieci (modyfikacja liczby neuronów, łączenie dwóch sieci, losowa przebudowa struktury itp.). Do oceny skuteczności są gotowe funkcje błędu, korelacji i wskaźnik AR.
Przykład
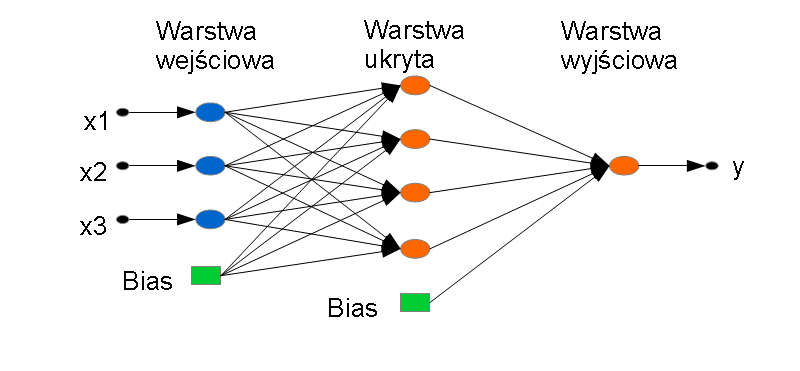
neural_net nn(3,4,logistic,logistic); nn.set_patterns(x1,y1,learn_set); nn.set_patterns(x2,y2,valid_set); nn.set_patterns(x3,y3,test_set); nn.init(); nn.learn(); double y = nn.value(x);
Tworzona jest sieć neuronowa 'nn’ o 3 wejściach, 4 neuronach ukrytych i funkcjach aktywacji warstw typu logistic. Następnie do sieci podawane są wzorce zmiennych objaśniających x1, x2, x3 i objaśnianych y1, y2, y3 (są to macierze). Standardowo, wypełnia się 3 zbiory danych (uczący, walidacyjny i testowy). Potem sieć jest inicjowana i uczona. Na koniec pokazane jest, jak z skorzystać z sieci, aby wyliczyć wartość 'y’ dla pojedynczego przypadku 'x’.
Struktura przykładowej sieci:
Scoring (score)
Została przygotowana specjalna biblioteka o nazwie „score”, wspomagająca programowanie scoringów. Dołącza się ją za pomocą:
#include <score.h>
Dostarczone są funkcje do:
- liczenia współczynników korelacji monotonicznej dla zmiennych ciągłych i binarnych
- wyznaczania kierunku zależności zmiennych
- obliczania wartości informacyjnej
- podziału na grupy zmiennych ciągłych (przedziały równoliczne lub równoodległe)
- zestaw różnych funkcji kodujących wraz z pochodnymi
- ustawiające parametry startowe przed estymacją
- do modelowania liniowego (m.in. statystyki istotności współczynników)
- do regresji logistycznej
- do oceny skuteczności modelu (AR, KS, CAP, TA)
- do wykonywania transformaty ortogonalnej
Przykład modelowania liniowego i logistycznego:
matrix dane.readtxt("dane.txt");
matrix x=dane["WIEK"],
y=dane["PD"];
matrix model_lin = lm_par(x,y);
matrix model_log = logistic_par(x,y);
Wyestymowane parametry modeli są w macierzy model_lin i model_log. Obliczenie wartości odbywa się tak:
matrix y2_lin,
y2_log;
y2_lin = lm_val(x2,model_lin);
y2_log = logistic_val(x2,model_log);
Dla wektora x2 są obliczane wartości modelu liniowego (y2_lin) i logistycznego (y2_log).
Wykres (gplot)
Do rysowania wykresów można użyć narzędzia Gnuplot (http://www.gnuplot.info/) i biblioteki „gplot”. Dołącza się ją za pomocą:
#include <gplot.h>
Standardowo wykresy zapisywane są z rozszerzeniem plt, dlatego w systemie powinna być zainstalowana przeglądarka Gnuplot. Jest to format wektorowy, który pozwala na interaktywne przeskalowanie wykresu, powiększanie wybranych fragmentów lub obracanie wykresów trójwymiarowych.
Aby narysować wykres, trzeba zdefiniować zmienną typu ‘gplot’. Z jej pomocą z poziomu programu C++ generuje się skrypt Gnuplot (plik plt). Dostępne funkcje opisane są w Pomocy HL++. Szczegółowy opis parametrów, jakie można nadać elementom wykresu, zawiera Pomoc (Help) programu Gnuplot.
Przykład 1.
Rysowanie wykresu funkcji sinus na podstawie danych z macierzy:
matrix sinus=~forall(seq(0,0.01,6),sin);// dane do narysowania
gplot gp("sample1"); // obiekt rysujący i nazwa pliku plt
gp.plot(sinus); // rysowanie krzywej
gp.pause(); // oczekiwanie na przejście do kolejnego wykresu
Na dysku zostanie utworzony plik „sample1.plt” z wykresem funkcji sinus, który można obejrzeć przeglądarką Gnuplot.
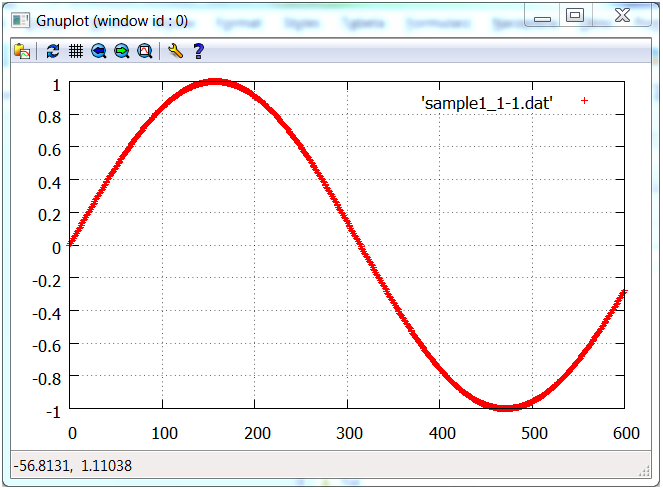
Przykład 2.
Rysowanie wykresu funkcji sinus zdefiniowanej wzorem:
gplot gp("sample2"); // obiekt rysujący i nazwa pliku plt
gp.xrange(0,6); // zakres wartości na osi X
gp.plot("sin(x)"); // rysowanie krzywej
gp.pause(); // oczekiwanie na przejście do kolejnego wykresu
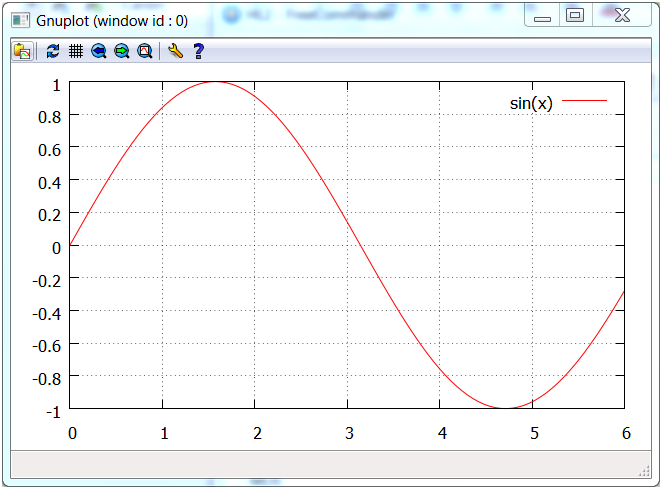
Raport HTML (html)
Do tworzenie raportów w html-u można użyć biblioteki „html”. Dołącza się ją za pomocą:
#include <html.h>
Aby utworzyć raport, trzeba zdefiniować zmienną typu ‘html’. Z jej pomocą z poziomu programu C++ generuje się plik html. Do raportu można dodawać tekst, obrazy, hiperłącza wewnętrzne/zewnętrzne oraz obiekty HL++, takie jak macierze, tabele i wykresy gplot. Obsługiwany są również dowolne JavaScripty. Można konfigurować format dodawanego tekstu i wygląd tabel. Opis dostępnych funkcji i ich parametrów znajduje się w pliku Pomocy HL++.
Przykład
Tworzenie raportu html:
html raport("Przykladowy raport"); // deklaracja obiektu raport
raport.tab("Pierwsza zakładka"); // zdefiniowanie pierwszej zakładki
text_properties wlasciwosci1; // deklaracja właściwości tekstu
wlasciwosci1.bold=1; // wybrany tekst pogrubiony
raport.htext("Jakis napis",wlasciwosci1); // dodanie tekstu do raportu
raport.image("obrazek.png"); // dodanie ilustracji
table_properties wlasciwosci2; // domyślne formatowanie tabeli
raport.hmatrix(macierz,c(2,6,0,-3),wlasciwosci2); // dodanie macierzy do raportu
/* pierwsza kolumna macierzy będzie wyświetlana z dokładnością do 2 miejsc po przecinku, druga kolumna z dokładnością 6 miejsc, trzecia jako liczby całkowite, a czwarta procentowo z dokładnością do 3 miejsc) */
raport.href("rodzial2.html"); // dodanie łącza do drugiego pliku
raport.js("wykres1.js"); // dodanie wykresu gplot
/* wykres należy wygenerować za pomocą biblioteki gplot, ustawiając wyjście jako JavaScript instrukcją Gnuplot: set terminal canvas */
raport.save("C://Temp//","raport.html"); // zapisanie raportu
Na dysku zostanie utworzony plik „raport.html”, który można obejrzeć w przeglądarce internetowej.
Symulacje i kwantyle (simulation, quantiles)
HL++ posiada specjalne obiekty służące do wykonywania symulacji Monte-Carlo. Biblioteka „simulation” pozwala na wykonanie dowolnej liczby symulacji nieograniczonej pamięcią komputera, ponieważ wyniki są przetwarzane w locie. Symulacje można przerwać w dowolnym momencie i obejrzeć wyniki, np. średnią lub wariancję rozkładu. Dostępne są różne statystyki opisowe, takie jak minimum, maksimum, średnie różnego rodzaju, skośność czy kurtoza. Wynikiem może też być rozkład reprezentowany przez histogram. Opis wszystkich dostępnych funkcji znajduje się w pliku Pomocy HL++. Symulacje można kontynuować i przerywać w dowolnym momencie, aby sprawdzić wyniki. Obiekty typu 'simulation’ można również dodawać do siebie, tym samym sumując wyniki osobnych symulacji. Przykładowo, wykonać 10 zestawów symulacji z 1 mln losowań, a następnie błyskawicznie dodać je do siebie i otrzymać jeden zestaw zawierający 10 mln losowań.
Bibiotekę „simulation” dołącza się za pomocą:
#include <simulation.h>
Przykład 1.
int seed[1]={1}; // ziarno generatora losowego
simulation s(-4.0,4.0); // deklaracja symulacji
/* histogram będzie w zakresie od -4 do 4 */
for (long n=1; n<=10000; n++) // wykonanych zostanie 10 tys. symulacji
{
s.add(normal_sample(0.0,1.0,seed)); // symulacje są gromadzone w obiekcie
}
cout<<"srednia="<<s.mean()<<endl; // średnia wartość
cout<<"odchylenie="<<s.stdev()<<endl; // odchylenie standardowe
cout<<"skosnosc="<<s.skewness()<<endl; // skośność rozkładu
cout<<"kurtoza="<<s.kurtosis()<<endl; // kurtoza rozkładu
(s.hist()).display("histogram"); // histogram
Druga bibioteka przeznaczona jest do obliczania kwantyli (również w locie). Dołącza się ją za pomocą:
#include <quantiles.h>
Przykład 2.
int seed[1]={1}; // ziarno generatora losowego
quantiles q1(0.25); // deklaracja 1. kwartyla
quantiles q2(0.5); // deklaracja mediany
quantiles q3(0.75); // deklaracja 3. kwartyla
for (long n=1; n<=10000; n++) // wykonanych zostanie 10 tys. symulacji
{
x=normal_sample(0.0,1.0,seed); // pojedyncza symulacja
q1.add(x); // dodanie symulacji do obiektu q1
q2.add(x); // dodanie symulacji do obiektu q2
q3.add(x); // dodanie symulacji do obiektu q3
}
cout<<"1.kwartyl="<<q1.result ()<<endl; // wyznaczenie 1. kwartyla
cout<<"mediana="<<q2.result ()<<endl; // wyznaczenie mediany
cout<<"3.kwartyl="<<q3.result()<<endl; // wyznaczenie 3. kwartyla
SQL (sql)
Do łączenia z bazą Oracle służy biblioteka 'sql’. Do jej działania potrzebna jest biblioteka OCCI (Oracle C++ Call Interface). Bibliteka umożliwia wykonanie zapytania SQL (wyciągnięcie danych) oraz załadowanie macierzy lub tabeli HL++ do tabeli Oracle.
Dołączenie biblioteki do programu:
#include <sql.h>
I poprzez dodanie plików „sql.h” i „sql.cpp” do projektu.
Przykład
table tab; sql_statement(tab,"uzytkownik","haslo","baza","select * from tabela1"); ora_loader(tab,"uzytkownik","haslo","baza","tabela2");
W powyższym przykładzie dane są najpierw wczytywane z bazy z „tabela1” do tabeli HL++ 'tab’, a następnie zapisywane z powrotem do bazy jako 'tabela2′.
Język R (rcppconv, rrun, CB tools)
HL++ posiada mechanizmy umożliwiające uruchamianie programów napisanych R, integrację kodu C++ z kodem R oraz narzędzia ułatwiające pracę z kodami języka R w środowisku Code::Blocks. Rozwiązanie bazuje na bibliotekach Rcpp i RInside. W systemie musi być zainstalowany R oraz pakiety Rcpp i RInside (pakiety R). Konfigurację środowiska Code::Blocks opisano w poniższej ramce.
Konfiguracja Rcpp i RInside w Code::Blocks pod Windows. Należy ustawić:
a) ścieżki do plików nagłówkowych (Search directories/Compiler):
C:\Program Files\R\R-3.5.1\include
C:\Program Files\R\R-3.5.1\library\Rcpp\include
C:\Program Files\R\R-3.5.1\library\RInside\include
b) ścieżki do bibliotek (Search directories/Linker):
C:\Program Files\R\R-3.5.1\bin\i386
C:\Program Files\R\R-3.5.1\library\Rcpp\libs\i386
C:\Program Files\R\R-3.5.1\library\RInside\libs\i386
c) Ustawienie linkera (Link libraries): R RInside Rlapack Rblas
d) Do pliku autoexec.bat należy dopisać:
SET R_HOME=C:\Program Files\R\R-3.5.1\
SET PATH=%PATH%;C:\Program Files\R\R-3.5.1\bin\i386;C:\Program Files\R\R-3.5.1\library\RInside\lib\i386
Biblioteka „rcppconv” to zestaw deklaracji typów R i konwerterów z C++ do R i odwrotnie (np. macierz R można skonwertować do C++ lub z C++ do R). Biblioteka „rrun” to zestaw funkcji do uruchamiania plików R i funkcji R. „Rcppconv” jest podłączona do „rrun”, dlatego w programie wystarczy dołączyć tylko tę ostatnią.
Dołączenie biblioteki do programu:
#include <rrun.h>
Przykład
RInside RE; // utworzenie instancji środowiska R
source("funkcje_R.R"); // uruchomienie funkcji z pliku R
matrix M=zeros(10,10); // macierz w C++
use(M); // utworzenie zmiennej M w środowisku R
RMatrix A=eval("funkcja1(M)"); // uruchomienie funkcji w R, wynik zwracany do A
matrix B=cmatrix(A); // konwersja macierzy A na macierz C++
Opcjonalnie, Code::Blocks można skonfigurować do pracy z kodami R wykorzystując R Tools. Dostępny jest lekser języka R, odpowiedzialny za kolorowanie składni oraz narzędzia do uruchamiania i debugowania kodów R oraz dostępu do pomocy R.
Przykładowy widok kodu R w Code::Blocks:
Biblioteki pomocnicze (console, progress, tasks)
Biblioteki pomocnicze są wykorzystywane przez inne biblioteki. Z biblioteki „console”, „progress” i „tasks” można korzystać niezależnie we własnych programach. Lista bibliotek:
- console – formatowanie tekstu wyświetlanego w konsoli (kolory, położenie kursora itp.)
- crossfun – zapewnia jednakowy zestaw funkcji w Windows i pod Linuxem
- error – obsługa komunikatów błędów dla typów złożonych
- platform – tu definiuje się system operacyjny, pod którym się pracuje
- progress – odpowiada za pokazywanie postępu np. przy zapisywaniu pliku
- data_dec – deklaracja zapowiadająca funkcje zaprzyjaźnione z typem „data”
- eltemp – elementarne konwersje dla typu „data”
- sort – sortowanie systemowe dla typu „data”
- tasks – obliczenia równoległe z synchronizacją zadań za pomocą pliku